有时候我们爬取网页数据,并不希望看其中的过程,只想看到最后的数据结果就可以了,这时候,***面就很有必要了!
代码如下
from selenium import webdriver from time import sleep #实现无可视化界面 from selenium.webdriver.chrome.options import Options #实现规避检测 from selenium.webdriver import ChromeOptions #实现无可视化界面的操作 chrome_options = Options() chrome_options.add_argument(\'--headless\') chrome_options.add_argument(\'--disable-gpu\') #实现规避检测 option = ChromeOptions() option.add_experimental_option(\'excludeSwitches\', [\'enable-automation\']) #如何实现让selenium规避被检测到的风险 bro = webdriver.Chrome(executable_path=\'./chromedriver\',chrome_options=chrome_options,options=option) #无可视化界面(无头浏览器) phantomJs bro.get(\'https://www.baidu.com\') print(bro.page_source) sleep(2) bro.quit()
运行效果:
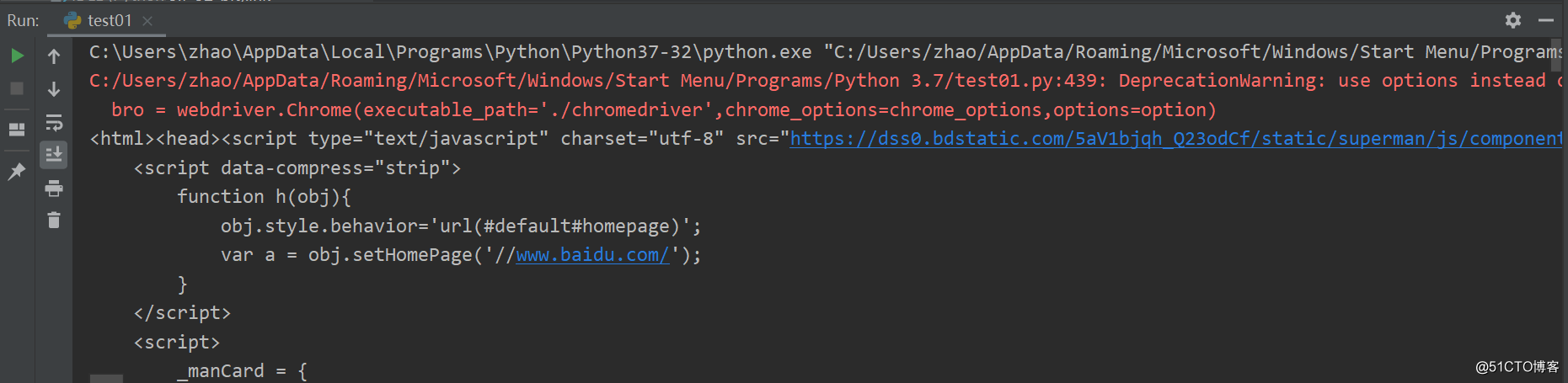
打印出网页代码,证明爬取网站信息成功
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。










![聊聊Python中关于a=[[]]*3的反思](http://www.ox520.com/wp-content/themes/ceomax-pro/timthumb.php?src=http://www.ox520.com/wp-content/uploads/2025/01/cb628726ebc95d43fa675ea4107acdec.png&h=200&w=300&zc=1&a=t&q=100&s=1)

