实验环境
1.安装Python 3.7
2.安装requests, bs4,pymysql 模块
实验步骤1.安装环境及模块
可参考https://www.jb51.net/article/194104.htm
2.编写代码
# 51cto 博客页面数据插入mysql数据库
# 导入模块
import re
import bs4
import pymysql
import requests
# 连接数据库账号密码
db = pymysql.connect(host=\'172.171.13.229\',
user=\'root\', passwd=\'abc123\',
db=\'test\', port=3306,
charset=\'utf8\')
# 获取游标
cursor = db.cursor()
def open_url(url):
# 连接模拟网页访问
headers = {
\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/57.0.2987.98 Safari/537.36\'}
res = requests.get(url, headers=headers)
return res
# 爬取网页内容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, \'html.parser\')
# 博客名
titles = []
targets = soup.find_all(\"a\", class_=\"tit\")
for each in targets:
each = each.text.strip()
if \"置顶\" in each:
each = each.split(\' \')[0]
titles.append(each)
# 阅读量
reads = []
read1 = soup.find_all(\"p\", class_=\"read fl on\")
read2 = soup.find_all(\"p\", class_=\"read fl\")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 评论数
comment = []
targets = soup.find_all(\"p\", class_=\'comment fl\')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all(\"p\", class_=\'collect fl\')
for each in targets:
collects.append(each.text)
# 发布时间
dates=[]
targets = soup.find_all(\"a\", class_=\'time fl\')
for each in targets:
each = each.text.split(\':\')[1]
dates.append(each)
# 插入sql 语句
sql = \"\"\"insert into blog (blog_title,read_number,comment_number, collect, dates)
values( \'%s\', \'%s\', \'%s\', \'%s\', \'%s\');\"\"\"
# 替换页面 \\xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub(\'\\s\', \'\', reads)
comment = re.sub(\'\\s\', \'\', comment)
collects = re.sub(\'\\s\', \'\', collects)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 统计总页数
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, \'html.parser\')
depth = soup.find(\'li\', class_=\'next\').previous_sibling.previous_sibling.text
return int(depth)
# 主函数
def main():
host = \"https://blog.51cto.com/13760351\"
res = open_url(host) # 打开首页链接
depth = find_depth(res) # 获取总页数
# 爬取其他页面信息
for i in range(1, depth + 1):
url = host + \'/p\' + str(i) # 完整链接
res = open_url(url) # 打开其他链接
find_text(res) # 爬取数据
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
if __name__ == \'__main__\':
main()
3..MySQL创建对应的表
CREATE TABLE `blog` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT \'主键\', `blog_title` varchar(52) DEFAULT NULL COMMENT \'博客标题\', `read_number` varchar(26) DEFAULT NULL COMMENT \'阅读数量\', `comment_number` varchar(16) DEFAULT NULL COMMENT \'评论数量\', `collect` varchar(16) DEFAULT NULL COMMENT \'收藏数量\', `dates` varchar(16) DEFAULT NULL COMMENT \'发布日期\', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;

4.运行代码,查看效果:
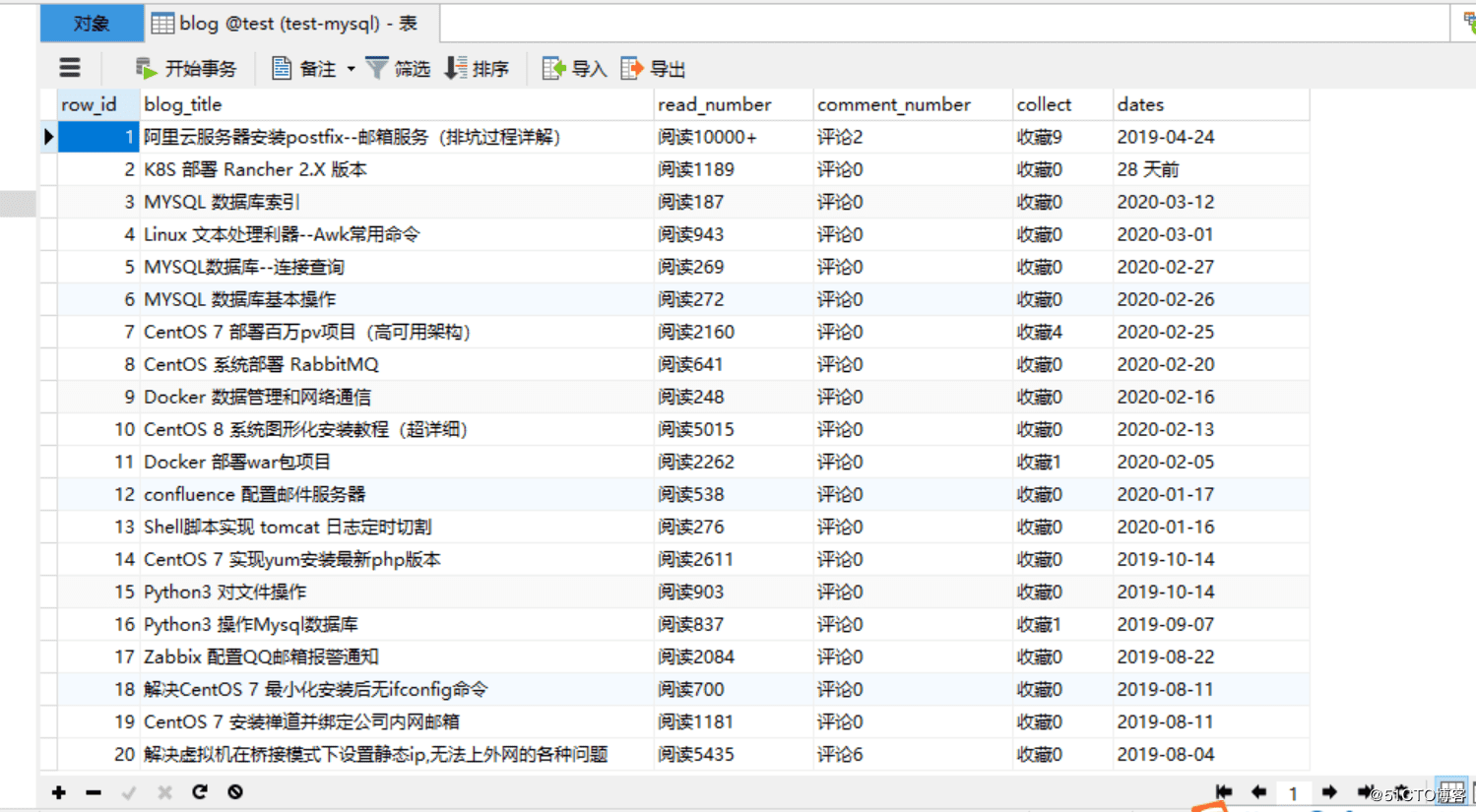
改进版:
改进内容:
1.数据库里面的某些字段只保留数字即可
2.默认爬取的内容都是字符串,存放数据库的某些字段,最好改为整型,方便后面数据库操作
1.代码如下:
import re
import bs4
import pymysql
import requests
# 连接数据库
db = pymysql.connect(host=\'172.171.13.229\',
user=\'root\', passwd=\'abc123\',
db=\'test\', port=3306,
charset=\'utf8\')
# 获取游标
cursor = db.cursor()
def open_url(url):
# 连接模拟网页访问
headers = {
\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/57.0.2987.98 Safari/537.36\'}
res = requests.get(url, headers=headers)
return res
# 爬取网页内容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, \'html.parser\')
# 博客标题
titles = []
targets = soup.find_all(\"a\", class_=\"tit\")
for each in targets:
each = each.text.strip()
if \"置顶\" in each:
each = each.split(\' \')[0]
titles.append(each)
# 阅读量
reads = []
read1 = soup.find_all(\"p\", class_=\"read fl on\")
read2 = soup.find_all(\"p\", class_=\"read fl\")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 评论数
comment = []
targets = soup.find_all(\"p\", class_=\'comment fl\')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all(\"p\", class_=\'collect fl\')
for each in targets:
collects.append(each.text)
# 发布时间
dates=[]
targets = soup.find_all(\"a\", class_=\'time fl\')
for each in targets:
each = each.text.split(\':\')[1]
dates.append(each)
# 插入sql 语句
sql = \"\"\"insert into blogs (blog_title,read_number,comment_number, collect, dates)
values( \'%s\', \'%s\', \'%s\', \'%s\', \'%s\');\"\"\"
# 替换页面 \\xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub(\'\\s\', \'\', reads)
reads=int(re.sub(\'\\D\', \"\", reads)) #匹配数字,转换为整型
comment = re.sub(\'\\s\', \'\', comment)
comment = int(re.sub(\'\\D\', \"\", comment)) #匹配数字,转换为整型
collects = re.sub(\'\\s\', \'\', collects)
collects = int(re.sub(\'\\D\', \"\", collects)) #匹配数字,转换为整型
dates = re.sub(\'\\s\', \'\', dates)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 统计总页数
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, \'html.parser\')
depth = soup.find(\'li\', class_=\'next\').previous_sibling.previous_sibling.text
return int(depth)
# 主函数
def main():
host = \"https://blog.51cto.com/13760351\"
res = open_url(host) # 打开首页链接
depth = find_depth(res) # 获取总页数
# 爬取其他页面信息
for i in range(1, depth + 1):
url = host + \'/p\' + str(i) # 完整链接
res = open_url(url) # 打开其他链接
find_text(res) # 爬取数据
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
#主程序入口
if __name__ == \'__main__\':
main()
2.创建对应表
CREATE TABLE `blogs` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT \'主键\', `blog_title` varchar(52) DEFAULT NULL COMMENT \'博客标题\', `read_number` int(26) DEFAULT NULL COMMENT \'阅读数量\', `comment_number` int(16) DEFAULT NULL COMMENT \'评论数量\', `collect` int(16) DEFAULT NULL COMMENT \'收藏数量\', `dates` varchar(16) DEFAULT NULL COMMENT \'发布日期\', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
3.运行代码,验证
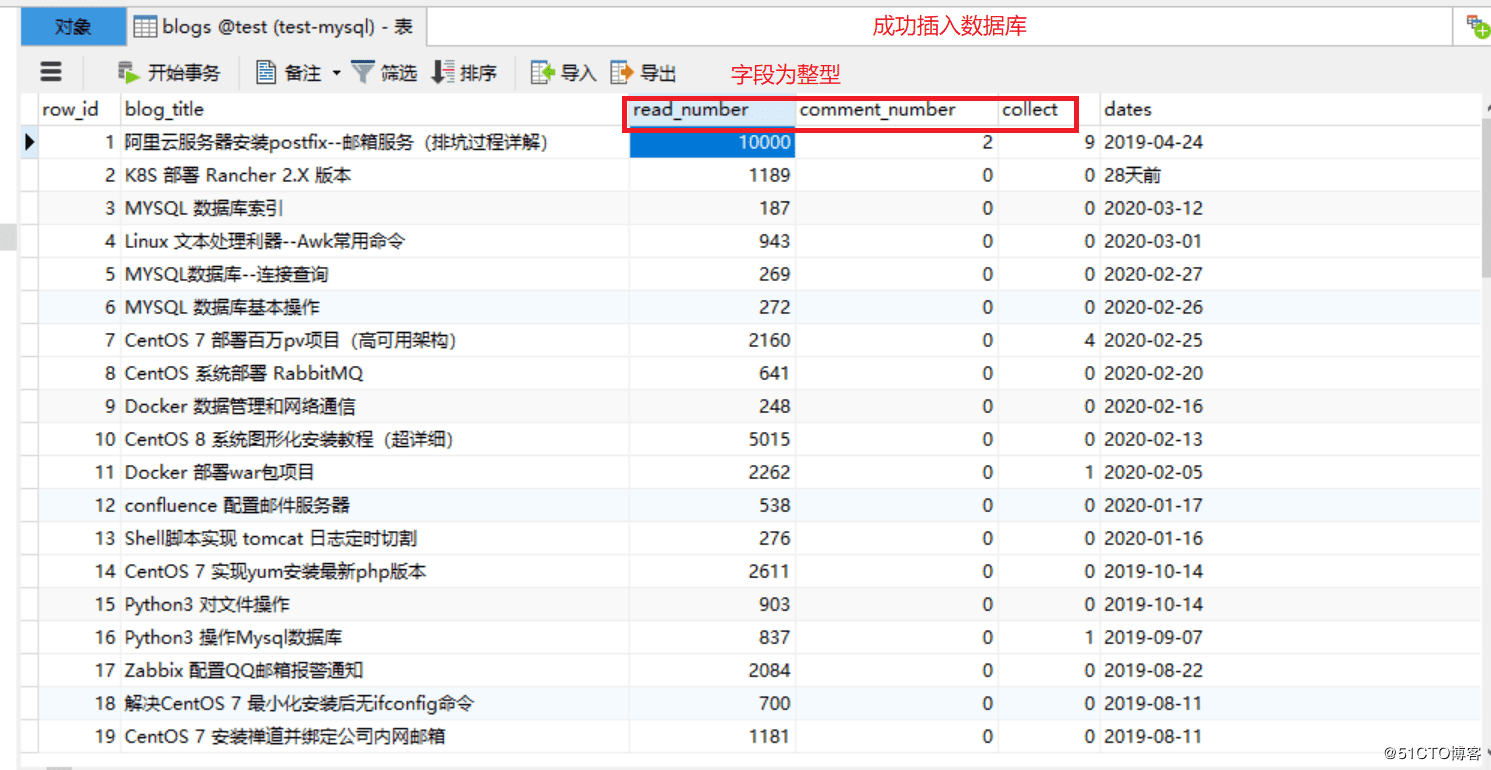
升级版
为了能让小白就可以使用这个程序,可以把这个项目打包成exe格式的文件,让其他人,使用电脑就可以运行代码,这样非常方便!
1.改进代码:
#末尾修改为: if __name__ == \'__main__\': main() print(\"\\n\\t\\t所有数据已成功存放数据库!!! \\n\") time.sleep(5)
2.安装打包模块pyinstaller(cmd安装)
pip install pyinstaller -i https://pypi.tuna.tsinghua.edu.cn/simple/
3.Python代码打包
1.切换到需要打包代码的路径下面
2.在cmd窗口运行 pyinstaller -F test03.py (test03为项目名称)
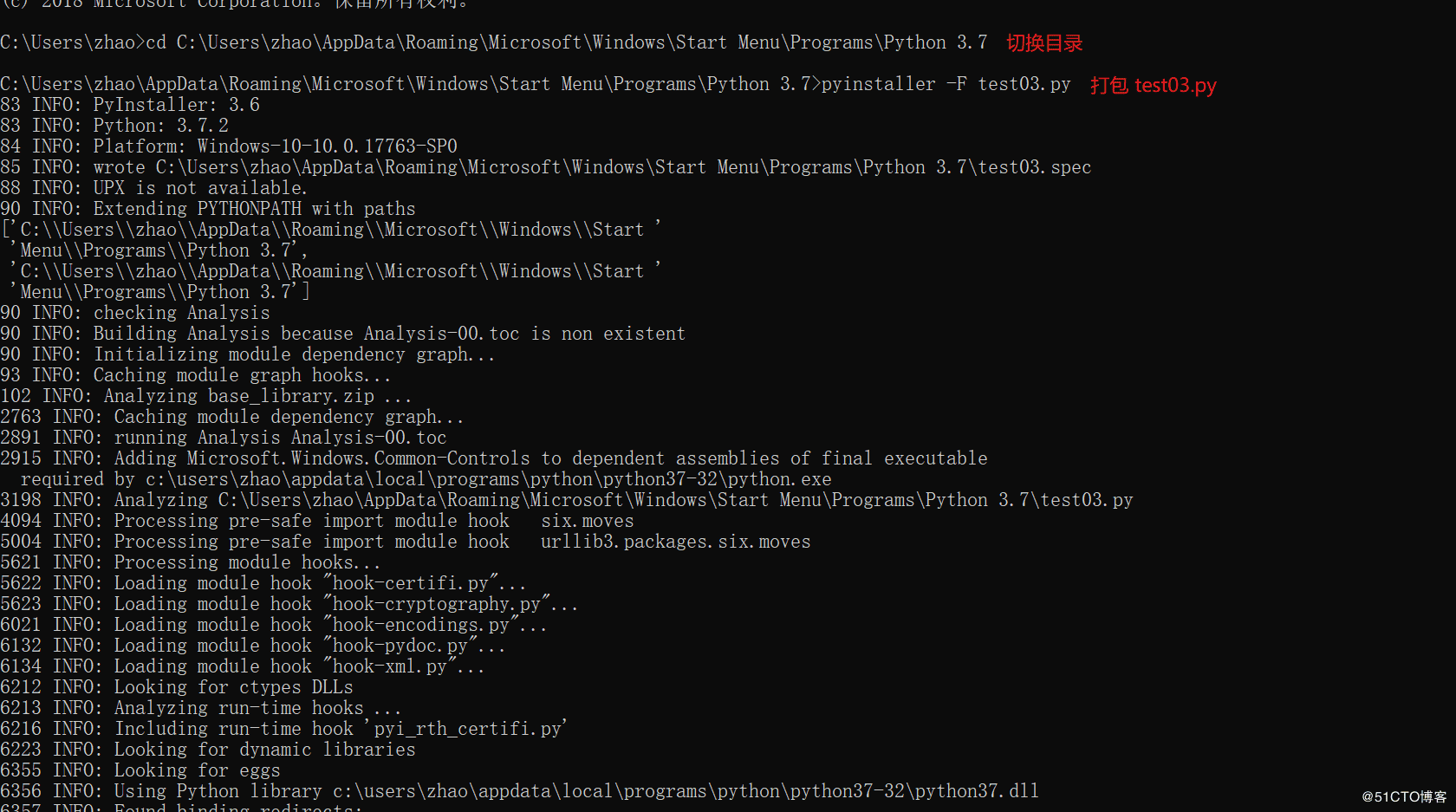
4.查看exe包
在打包后会出现dist目录,打好包就在这个目录里面

5.运行exe包,查看效果
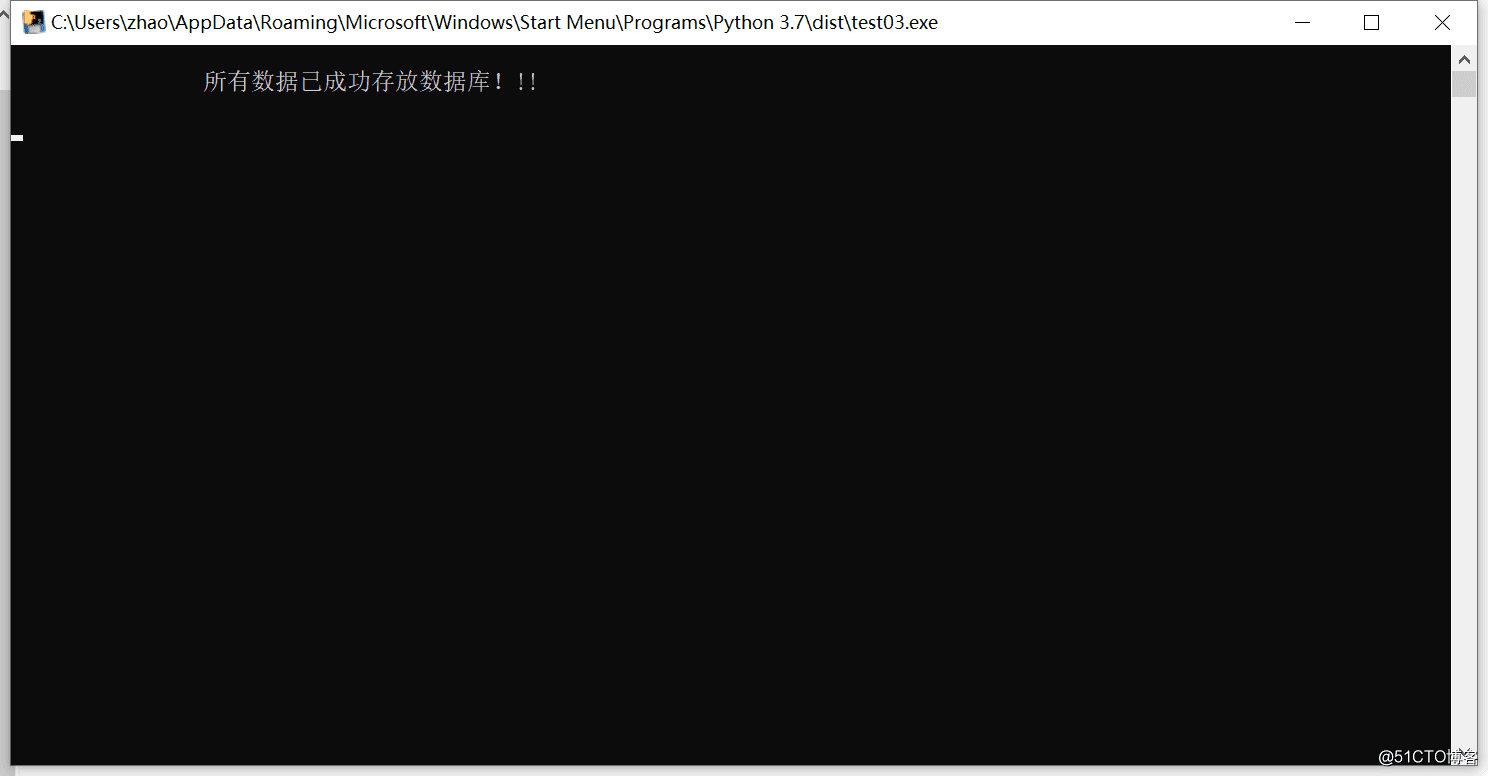
检查数据库
总结:
1.这一篇博客,是在上一篇的基础上改进的,步骤是先爬取首页的信息,再爬取其他页面信息,最后在改进细节,打包exe文件
2.我们爬取网页数据大多数还是存放到数据库的,所以这种方法很实用。
3.其实在此博客的基础上还是可以改进的,重要的是掌握方法即可。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。












