requests库
利用pip安装:
pip install requests
基本请求
req = requests.get(\"https://www.baidu.com/\") req = requests.post(\"https://www.baidu.com/\") req = requests.put(\"https://www.baidu.com/\") req = requests.delete(\"https://www.baidu.com/\") req = requests.head(\"https://www.baidu.com/\") req = requests.options(https://www.baidu.com/)
1.get请求
参数是字典,我们可以传递json类型的参数:
import requests
from fake_useragent import UserAgent#请求头部库
headers = {\"User-Agent\":UserAgent().random}#获取一个随机的请求头
url = \"https://www.baidu.com/s\"#网址
params={
\"wd\":\"豆瓣\" #网址的后缀
}
requests.get(url,headers=headers,params=params)
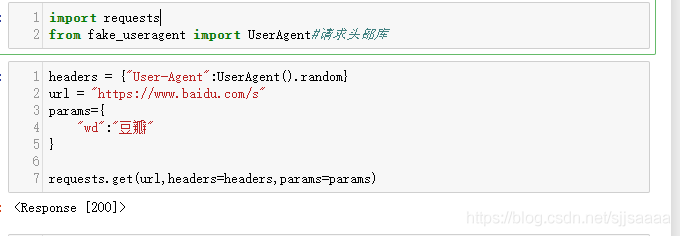
返回了状态码,所以我们要想获取内容,需要将其转成text:
#get请求
headers = {\"User-Agent\":UserAgent().random}
url = \"https://www.baidu.com/s\"
params={
\"wd\":\"豆瓣\"
}
response = requests.get(url,headers=headers,params=params)
response.text
2.post 请求
参数也是字典,也可以传递json类型的参数:
import requests
from fake_useragent import UserAgent
headers = {\"User-Agent\":UserAgent().random}
url = \"https://www.baidu.cn/index/login/login\" #登录账号密码的网址
params = {
\"user\":\"1351351335\",#账号
\"password\":\"123456\"#密码
}
response = requests.post(url,headers=headers,data=params)
response.text
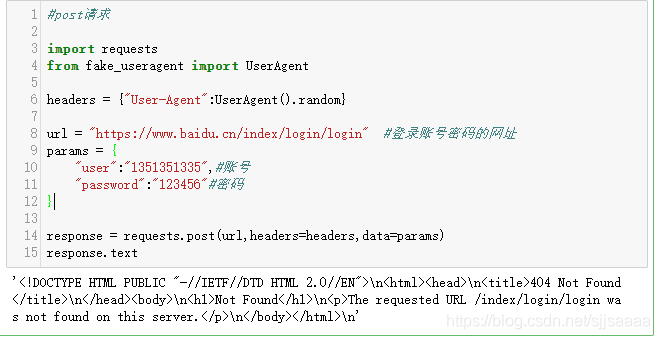
因为这里需要一个登录的网页,我这里就随便用了一个,没有登录,所以显示的结果是这样的,如果想要测试登录的效果,请找一个登录的页面去尝试一下。
3.IP代理
采集时为避免被封IP,经常会使用代理,requests也有相应 的proxies属性。
#IP代理
import requests
from fake_useragent import UserAgent
headers = {\"User-Agent\":UserAgent().random}
url = \"http://httpbin.org/get\" #返回当前IP的网址
proxies = {
\"http\":\"http://yonghuming:123456@192.168.1.1:8088\"#http://用户名:密码@IP:端口号
#\"http\":\"https://182.145.31.211:4224\"# 或者IP:端口号
}
requests.get(url,headers=headers,proxies=proxies)
代理IP可以去:快代理去找,也可以去购买。
http://httpbin.org/get。这个网址是查看你现在的信息:

4.设置访问超时时间
可以通过timeout属性设置超时时间,一旦超过这个时间还没获取到响应内容,就会提示错误。
#设置访问时间 requests.get(\"http://baidu.com/\",timeout=0.1)

5.证书问题(SSLError:HTTP)
ssl验证。
import requests
from fake_useragent import UserAgent #请求头部库
url = \"https://www.12306.cn/index/\" #需要证书的网页地址
headers = {\"User-Agent\":UserAgent().random}#获取一个随机请求头
requests.packages.urllib3.disable_warnings()#禁用安全警告
response = requests.get(url,verify=False,headers=headers)
response.encoding = \"utf-8\" #用来显示中文,进行转码
response.text

6.session自动保存cookies
import requests
from fake_useragent import UserAgent
headers = {\"User-Agent\":UserAgent().chrome}
login_url = \"https://www.baidu.cn/index/login/login\" #需要登录的网页地址
params = {
\"user\":\"yonghuming\",#用户名
\"password\":\"123456\"#密码
}
session = requests.Session() #用来保存cookie
#直接用session 歹意requests
response = session.post(login_url,headers=headers,data=params)
info_url = \"https://www.baidu.cn/index/user.html\" #登录完账号密码以后的网页地址
resp = session.get(info_url,headers=headers)
resp.text
因为我这里没有使用需要账号密码的网页,所以显示这样:

我获取了一个智慧树的网页
#cookie
import requests
from fake_useragent import UserAgent
headers = {\"User-Agent\":UserAgent().chrome}
login_url = \"https://passport.zhihuishu.com/login?service=https://onlineservice.zhihuishu.com/login/gologin\" #需要登录的网页地址
params = {
\"user\":\"12121212\",#用户名
\"password\":\"123456\"#密码
}
session = requests.Session() #用来保存cookie
#直接用session 歹意requests
response = session.post(login_url,headers=headers,data=params)
info_url = \"https://onlne5.zhhuishu.com/onlinWeb.html#/stdetInex\" #登录完账号密码以后的网页地址
resp = session.get(info_url,headers=headers)
resp.encoding = \"utf-8\"
resp.text

7.获取响应信息
| 代码 | 含义 |
|---|---|
| resp.json() | 获取响应内容 (以json字符串) |
| resp.text | 获取相应内容(以字符串) |
| resp.content | 获取响应内容(以字节的方式) |
| resp.headers | 获取响应头内容 |
| resp.url | 获取访问地址 |
| resp.encoding | 获取网页编码 |
| resp.request.headers | 请求头内容 |
| resp.cookie | 获取cookie |
到此这篇关于python爬虫利器之requests库的用法(超全面的爬取网页案例)的文章就介绍到这了,更多相关python爬虫requests库用法内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!












