介绍
我编写了一个快速且带有斑点的python脚本,以可视化nmap和masscan的结果。它通过解析来自扫描的XML日志并生成所扫描IP范围的直观表示来工作。以下屏幕截图是输出示例:
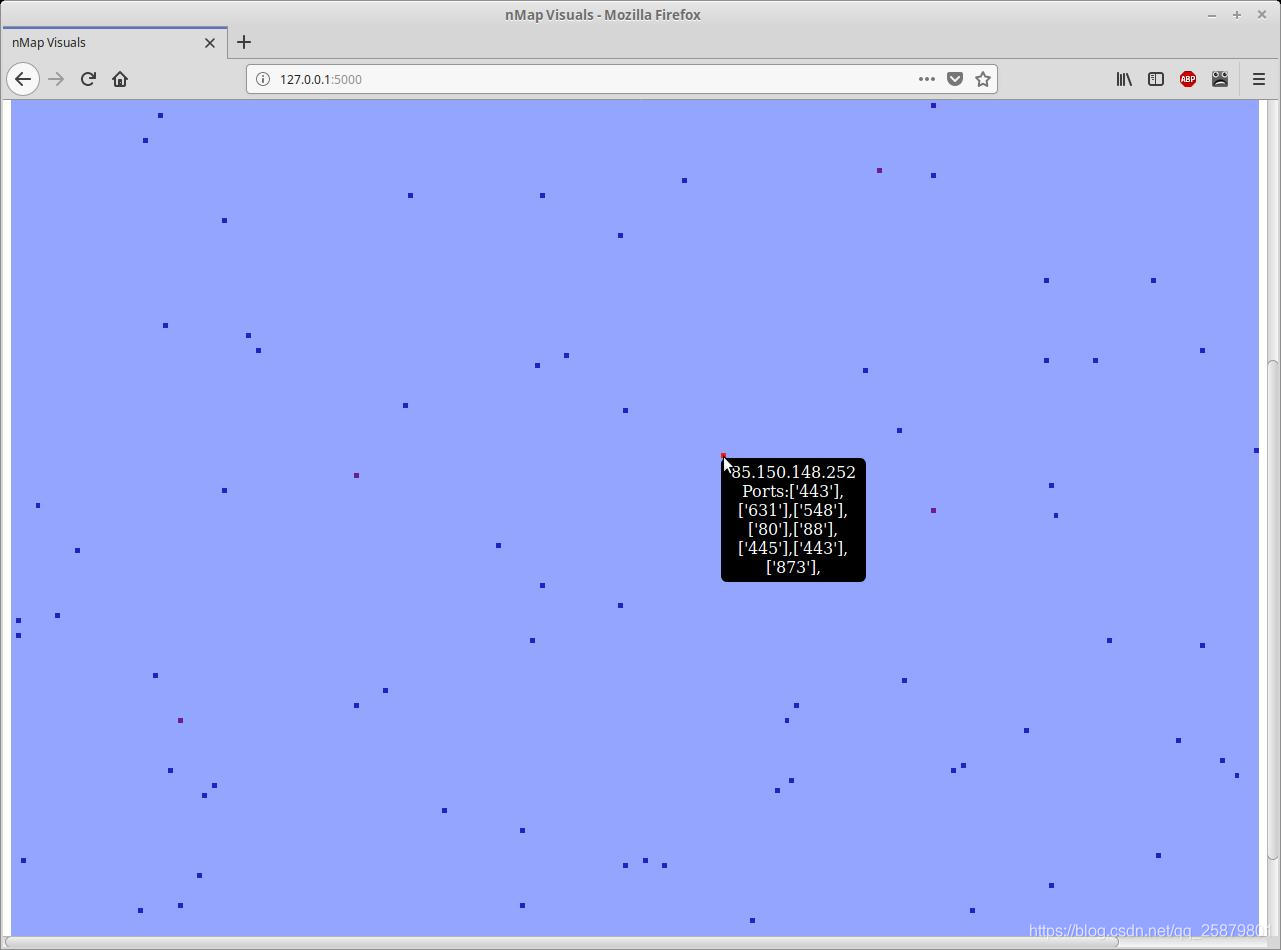
由于缺少更好的词,我将从现在开始将输出称为地图。每个主机由一个彩色正方形表示。覆盖地图大部分内容的浅蓝色方块表示主机处于脱机状态(或仅未响应masscan的SYN。)其他彩色方块表示处于联机状态且具有开放端口的主机。正方形的颜色从蓝色到红色。正方形越红,表示主机上打开的端口越多。将鼠标悬停在每个方块上,将在工具提示中显示IP地址和打开的端口。
该工具非常有用,因为它使您可以大致了解IP范围,而不必在日志文件中拖网。它使您可以轻松查看扫描中的主机块。该工具可以从github下载,但是我将在下面描述代码的工作方式。
如何使用
首先,我要说这段代码没有经过优化。我已经针对/ 21的日志运行了代码,并花费了大约40秒钟来生成输出映射。
第一步是查找运行扫描的IP地址范围。由于扫描命令未保存在日志文件中,因此这真是一个痛苦。因此,我们必须根据最低和最高IP结果来计算范围。我们从扫描中解析XML文件,并将扫描到的每个IP地址附加到名为ipList的列表中
ipList = [] for event, element in etree.iterparse(\'output.xml\', tag=\"host\"): for child in element: if child.tag == \'address\': ipList.append(child.attrib[\'addr\'])
然后,我们遍历ipList并将每个八位位组分成单独的列表,分别称为firstOctetRange,secondOctetRange,thirdOctetRang和forwardOctetRange。
firstOctetRange = [] secondOctetRange = [] thirdOctetRange = [] forthOctetRange = [] bitDelimeter = 0 startingIP = 0 endingIP = 0 for ip in ipList: binaryOctet = \'\' octets = ip.split(\'.\') firstOctetRange.append(int(octets[0])) secondOctetRange.append(int(octets[1])) thirdOctetRange.append(int(octets[2])) forthOctetRange.append(int(octets[3]))
然后,我们将每个结果的每个八位位组与另一个结果的相同八位位组进行比较,以确定值发生变化的八位位组。例如。如果前两个八位位组始终相同。我们知道扫描的CIDR表示法将大于/ 16。我使用了变量bitDelimeter来存储CIDR表示法截取的八位字节的值。
if min(firstOctetRange) != max(firstOctetRange): bitDelimeter = 0 elif min(secondOctetRange) != max(secondOctetRange): bitDelimeter = 1 elif min(thirdOctetRange) != max(thirdOctetRange): bitDelimeter = 2 elif min(forthOctetRange) != max(forthOctetRange): bitDelimeter = 3
扫描的IP地址范围被添加到称为parsedServers的有序字典中。ip地址是使用一系列4个嵌套的FOR循环生成的,每个循环在0 ? 256范围内循环。此范围开始的八位位组取决于bitDelimeter。例如。如果扫描了IP地址范围192.168.10.0/24。位定界符将为3,指示最后一个八位位组是更改其值的八位位组。因此,用于生成要放入parsedServers的IP地址的循环将固定前三个八位字节,并仅对最后一个八位字节循环范围为0 ? 256。如果我们扫描/ 21,则位定界符将为2,因此生成IP地址的循环将固定前两个八位位组。将根据扫描的最小第三八位字节值和扫描的最大第三八位字节值的范围生成第三八位字节。第四个八位位组的范围是0 ? 256。
if bitDelimeter == 0:
for one in range(min(firstOctetRange), max(firstOctetRange) + 1):
for two in range(0, 256):
for three in range(0, 256):
for four in range(0, 256):
ip = \"%d.%d.%d.%d\" % (one, two, three, four)
parsedServers[ip] = []
if bitDelimeter == 1:
one = min(firstOctetRange)
for two in range(min(secondOctetRange), max(secondOctetRange) + 1):
for three in range(0, 256):
for four in range(0, 256):
ip = \"%d.%d.%d.%d\" % (one, two, three, four)
parsedServers[ip] = []
if bitDelimeter == 2:
one = min(firstOctetRange)
two = min(secondOctetRange)
for three in range(min(thirdOctetRange), max(thirdOctetRange) + 1):
for four in range(0, 256):
ip = \"%d.%d.%d.%d\" % (one, two, three, four)
parsedServers[ip] = []
if bitDelimeter == 3:
one = min(firstOctetRange)
two = min(secondOctetRange)
three = min(thirdOctetRange)
for four in range(min(forthOctetRange), max(forthOctetRange) + 1):
ip = \"%d.%d.%d.%d\" % (one, two, three, four)
parsedServers[ip] = []
现在,我们有一个parsedServer排序的dict,其中包含我们扫描范围内的所有IP地址。下一步是将扫描中找到的打开端口添加到parsedServer字典中。
for event, element in etree.iterparse(\'output.xml\', tag=\"host\"):
for child in element:
if child.tag == \'address\':
ipAddress = child.attrib[\'addr\']
if child.tag == \'ports\':
for subChild in child:
port = [subChild.attrib[\'portid\']]
parsedServers[ipAddress].append(port)
现在,我们需要生成一个HTML页面,可用于可视化结果。这是使用Flask完成的。我们遍历包含所有数据的pasedServers字典。创建一个infoString,其中包含当前迭代的IP地址和端口。当光标悬停在地图上的正方形上时,将在工具提示中使用此功能。创建htmlBuffer并将其附加到parsedServers字典的每次迭代中。每次迭代都会添加HTML代码,以使用从colourRange列表中提取的颜色添加新的表格数据单元。范围中总地址的平方根表示何时需要在表中添加新行。这样可以使结果在页面上显示为正方形。
count = 0 htmlBuffer = Markup(\'\') for key, value in parsedServers.items(): infoString = str(key) + \'<br>\' if value: infoString += \'Ports:\' for portValue in value: infoString += str(portValue) + \',\' colourRange = [\'94A5FF\', \'0024E5\', \'2422C5\', \'4821A6\', \'6D1F87\', \'911E67\', \'B61C48\', \'DA1B29\', \'FF1A0A\'] htmlBuffer += Markup(\'<td class=\"tooltip\", bgcolor=\"\' + colourRange[len(value)] + \'\"><span class=\"tooltiptext\">\' + infoString + \'</span></td>\')<br> count += 1<br> if count > math.sqrt(len(parsedServers)):<br> htmlBuffer += Markup(\'</tr><tr>\') count = 0
例如。我们正在parsedServers中进行迭代,地址为192.168.10.22,并且打开了3个端口。将使用工具提示中列出的IP地址和端口创建一个表格数据单元。单元格的背景颜色将从包含9个十六进制颜色代码的colourRange列表中提取。列表上的索引越高,颜色越红色。在此示例中,IP地址有3个开放的端口。因此,第三个索引中的颜色将设置为背景色,从而使数据单元格变为紫色。
最后,我们将模板传递给htmlBuffer。然后运行Web服务器。通过浏览至127.0.0.1:5000,可以找到输出。
@app.route(\'/\') def index(): return render_template(\'index.html\', name=htmlBuffer) if __name__ == \'__main__\': app.run()
到此这篇关于利于python脚本编写可视化nmap和masscan的文章就介绍到这了,更多相关python编写可视化nmap和masscan内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!












