准备
首先安装爬虫urllib库
pip install urllib
获取有道翻译的链接url
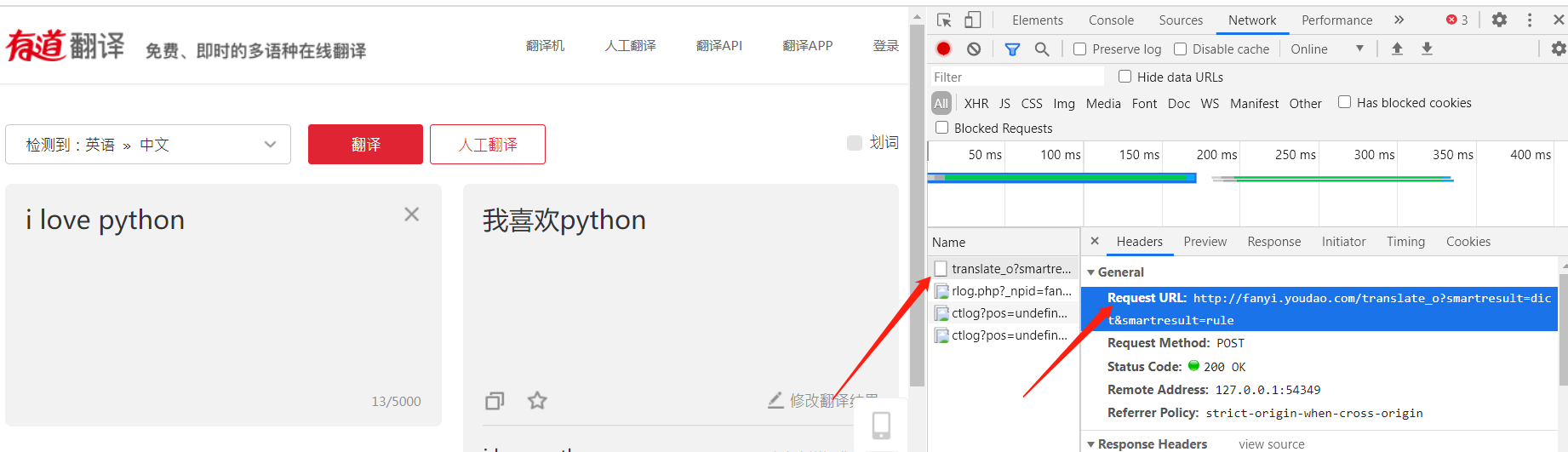
需要发送的参数在form data里
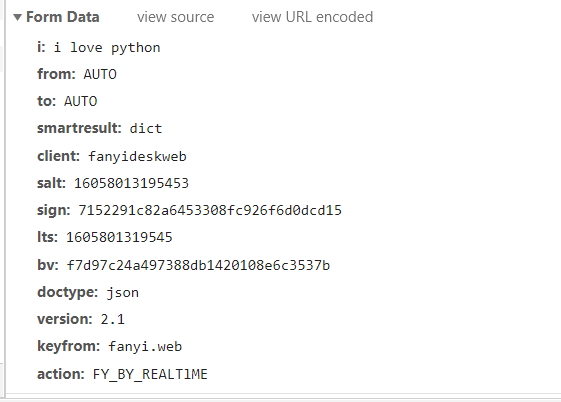
示例
import urllib.request
import urllib.parse
url = \'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule\'
data = {}
data[\'i\'] = \'i love python\'
data[\'from\'] = \'AUTO\'
data[\'to\'] = \'AUTO\'
data[\'smartresult\'] = \'dict\'
data[\'client\'] = \'fanyideskweb\'
data[\'salt\'] = \'16057996372935\'
data[\'sign\'] = \'0965172abb459f8c7a791df4184bf51c\'
data[\'lts\'] = \'1605799637293\'
data[\'bv\'] = \'f7d97c24a497388db1420108e6c3537b\'
data[\'doctype\'] = \'json\'
data[\'version\'] = \'2.1\'
data[\'keyfrom\'] = \'fanyi.web\'
data[\'action\'] = \'FY_BY_REALTlME\'
data = urllib.parse.urlencode(data).encode(\'utf-8\')
response = urllib.request.urlopen(url,data)
html = response.read().decode(\'utf-8\')
print(html)
运行会出现50的错误,这里需要将url链接的_o删除掉

删除后运行成功

但是这个结果看起来还是太复杂,需要在进行优化
导入json,然后转换成字典进行过滤
import urllib.request
import urllib.parse
import json
url = \'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule\'
data = {}
data[\'i\'] = \'i love python\'
data[\'from\'] = \'AUTO\'
data[\'to\'] = \'AUTO\'
data[\'smartresult\'] = \'dict\'
data[\'client\'] = \'fanyideskweb\'
data[\'salt\'] = \'16057996372935\'
data[\'sign\'] = \'0965172abb459f8c7a791df4184bf51c\'
data[\'lts\'] = \'1605799637293\'
data[\'bv\'] = \'f7d97c24a497388db1420108e6c3537b\'
data[\'doctype\'] = \'json\'
data[\'version\'] = \'2.1\'
data[\'keyfrom\'] = \'fanyi.web\'
data[\'action\'] = \'FY_BY_REALTlME\'
data = urllib.parse.urlencode(data).encode(\'utf-8\')
response = urllib.request.urlopen(url,data)
html = response.read().decode(\'utf-8\')
req = json.loads(html)
result = req[\'translateResult\'][0][0][\'tgt\']
print(result)

但是这个程序只能翻译一个单词,用完就废了。于是我在进行优化
import urllib.request
import urllib.parse
import json
def translate():
centens = input(\'输入要翻译的语句:\')
url = \'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule\'
head = {}#增加请求头,防反爬虫
head[\'User-Agent\'] = \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36\'
data = {}#带上from data的数据进行请求
data[\'i\'] = centens
data[\'from\'] = \'AUTO\'
data[\'to\'] = \'AUTO\'
data[\'smartresult\'] = \'dict\'
data[\'client\'] = \'fanyideskweb\'
data[\'salt\'] = \'16057996372935\'
data[\'sign\'] = \'0965172abb459f8c7a791df4184bf51c\'
data[\'lts\'] = \'1605799637293\'
data[\'bv\'] = \'f7d97c24a497388db1420108e6c3537b\'
data[\'doctype\'] = \'json\'
data[\'version\'] = \'2.1\'
data[\'keyfrom\'] = \'fanyi.web\'
data[\'action\'] = \'FY_BY_REALTlME\'
data = urllib.parse.urlencode(data).encode(\'utf-8\')
req = urllib.request.Request(url,data,head)
response = urllib.request.urlopen(req)
html = response.read().decode(\'utf-8\')
req = json.loads(html)
result = req[\'translateResult\'][0][0][\'tgt\']
# print(f\'中英互译的结果:{result}\')
return result
t = translate()
print(f\'中英互译的结果:{t}\')
优化完成,效果还行。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。












