一.思路
我们通过网页版的微信公众平台的图文消息中的超链接获取到我们需要的接口

从接口中我们可以得到对应的微信公众号和对应的所有微信公众号文章。
二.接口分析
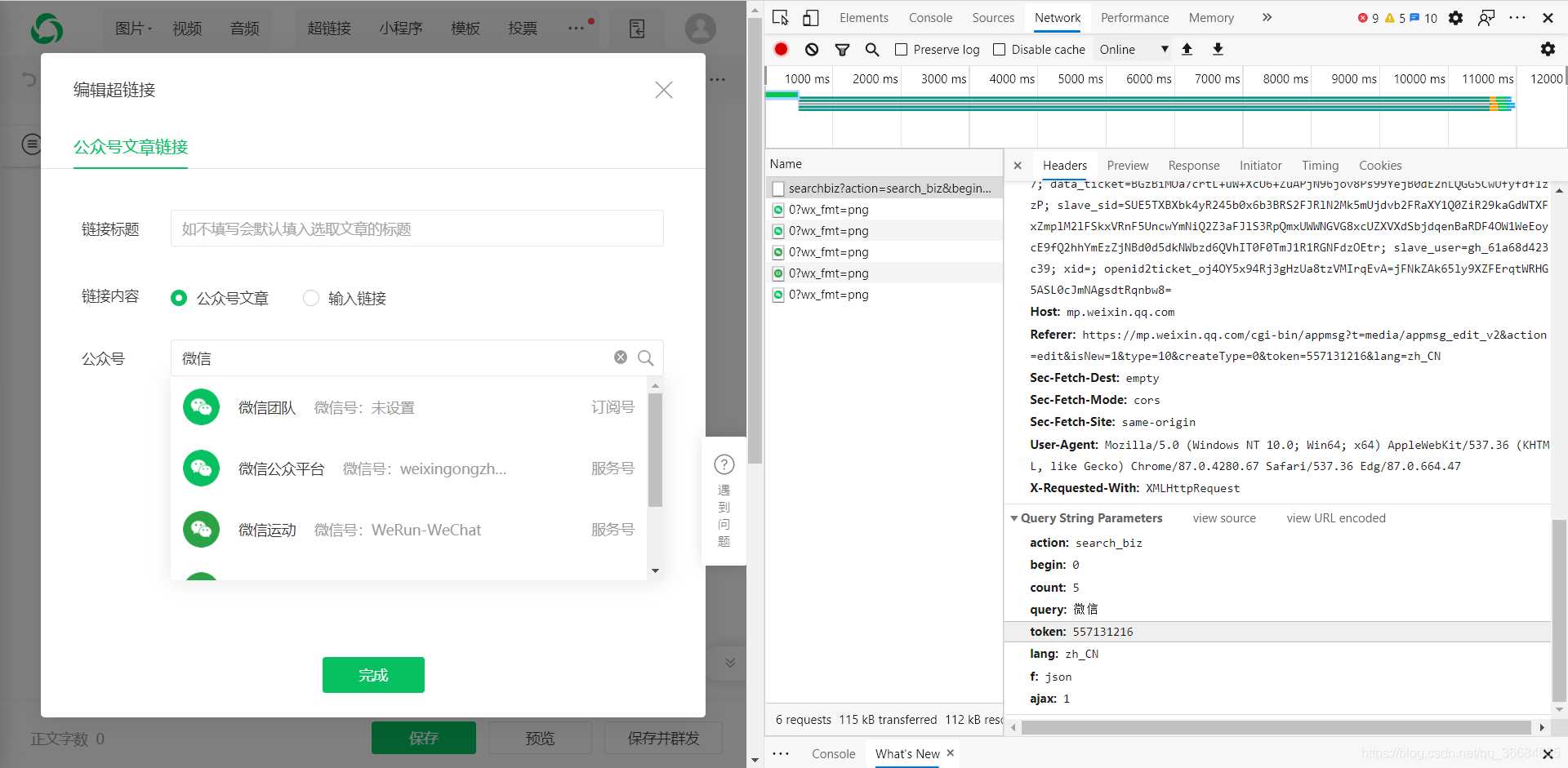
获取微信公众号的接口:
https://mp.weixin.qq.com/cgi-bin/searchbiz?
参数:
action=search_biz
begin=0
count=5
query=公众号名称
token=每个账号对应的token值
lang=zh_CN
f=json
ajax=1
请求方式:
GET
所以这个接口中我们只需要得到token即可,而query则是你需要搜索的公众号,token则可以通过登录后的网页链接获取得到。
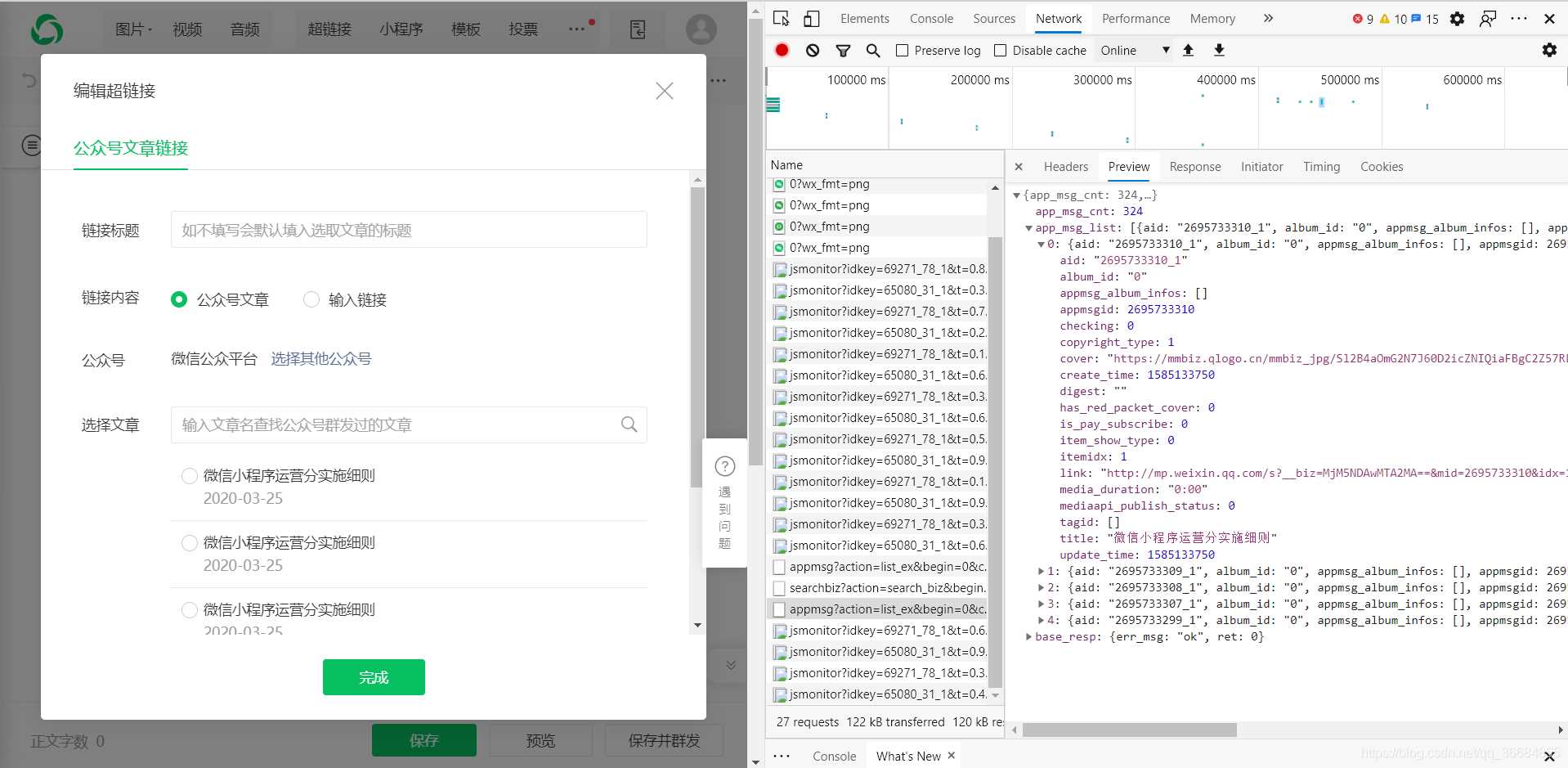
获取对应公众号的文章的接口:
https://mp.weixin.qq.com/cgi-bin/appmsg?
参数:
action=list_ex
begin=0
count=5
fakeid=MjM5NDAwMTA2MA==
type=9
query=
token=557131216
lang=zh_CN
f=json
ajax=1
请求方式:
GET
在这个接口中我们需要获取的值有上一步的token以及fakeid,而这个fakeid则在第一个接口中可以获取得到。从而我们就可以拿到微信公众号文章的数据了。
三.实现
第一步:
首先我们需要通过selenium模拟登录,然后获取到cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get(\'https://mp.weixin.qq.com/\')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath(\"//a[@class=\'login__type__container__select-type\']\").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath(\"//input[@name=\'account\']\")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath(\"//input[@name=\'password\']\")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath(\"//a[@class=\'btn_login\']\").click()
sleep(2)
# 微信登录验证
print(\'请扫描二维码\')
sleep(20)
# 刷新当前网页
browser.get(\'https://mp.weixin.qq.com/\')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item[\'name\']] = item[\'value\']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open(\'cookie.txt\', \'w+\', encoding=\'utf-8\') as f:
f.write(cookie_str)
print(\'cookie保存到本地成功\')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split(\'?\')[1].split(\'&\')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split(\'=\')[0]] = item.split(\'=\')[1]
# 返回token
return paramdict[\'token\']
定义了一个登录方法,里面的参数为登录的账号和密码,然后定义了一个字典用来存储cookie的值。通过模拟用户输入对应的账号密码并且点击登录,然后会出现一个扫码验证,用登录的微信去扫码即可。
刷新当前网页后,获取当前cookie以及token然后返回。
第二步:
1.请求获取对应公众号接口,取到我们需要的fakeid
url = \'https://mp.weixin.qq.com\'
headers = {
\'HOST\': \'mp.weixin.qq.com\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63\'
}
with open(\'cookie.txt\', \'r\', encoding=\'utf-8\') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = \'https://mp.weixin.qq.com/cgi-bin/searchbiz?\'
params = {
\'action\': \'search_biz\',
\'begin\': \'0\',
\'count\': \'5\',
\'query\': \'搜索的公众号名称\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
将我们获取到的token和cookie传进来,然后通过requests.get请求,获得返回的微信公众号的json数据
lists = search_resp.json().get(\'list\')[0]
通过上面的代码即可获取到对应的公众号数据
fakeid = lists.get(\'fakeid\')
通过上面的代码就可以得到对应的fakeid
2.请求获取微信公众号文章接口,取到我们需要的文章数据
appmsg_url = \'https://mp.weixin.qq.com/cgi-bin/appmsg?\'
params_data = {
\'action\': \'list_ex\',
\'begin\': \'0\',
\'count\': \'5\',
\'fakeid\': fakeid,
\'type\': \'9\',
\'query\': \'\',
\'token\': token,
\'lang\': \'zh_CN\',
\'f\': \'json\',
\'ajax\': \'1\'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入fakeid和token然后还是调用requests.get请求接口,获得返回的json数据。
我们就实现了对微信公众号文章的爬取。
四.总结
通过对微信公众号文章的爬取,需要掌握selenium和requests的用法,以及如何获取到请求接口。但是需要注意的是当我们循环获取文章时,一定要设置延迟时间,不然账号很容易被封禁,从而得不到返回的数据。
到此这篇关于Python 微信公众号文章爬取的示例代码的文章就介绍到这了,更多相关Python 微信公众号文章爬取内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!












